
标题
自动事实核查研究综述
作者和出处
Department of Computer Science and Technology University of Cambridge, UK(英国剑桥大学计算机科学与技术系)
摘要
事实核查在现代媒体生态系统中变得日益重要,因为信息和虚假信息在这种环境中的传播速度都非常快。因此,研究人员一直在探索如何自动化事实核查,使用自然语言处理、机器学习、知识表示和数据库等技术来自动预测断言的真实性。在本文中,我们概述了源自自然语言处理的自动化事实核查,并讨论了其与相关任务和学科的联系。在这个过程中,我们介绍了现有的数据集和模型,旨在统一各种定义并确定共同的概念。最后,我们强调了未来研究的挑战。
引言和结论
在本次调查中,我们全面且及时地概述了自动化事实核查,将先前研究中发展的各种定义统一到一个共同的框架中。我们首先定义了我们事实核查框架的三个阶段——主张检测、证据检索和主张验证,后者包括判决预测和证据生成。然后,我们概述了现有的数据集和建模策略,对这些进行分类,并将它们与我们的框架进行上下文关联。最后,我们讨论了已经解决的关键研究挑战,并为我们认为应该由未来研究解决的挑战提供方向。我们伴随着调查的一个存储库,其中列出了我们在调查中提到的资源。
任务定义
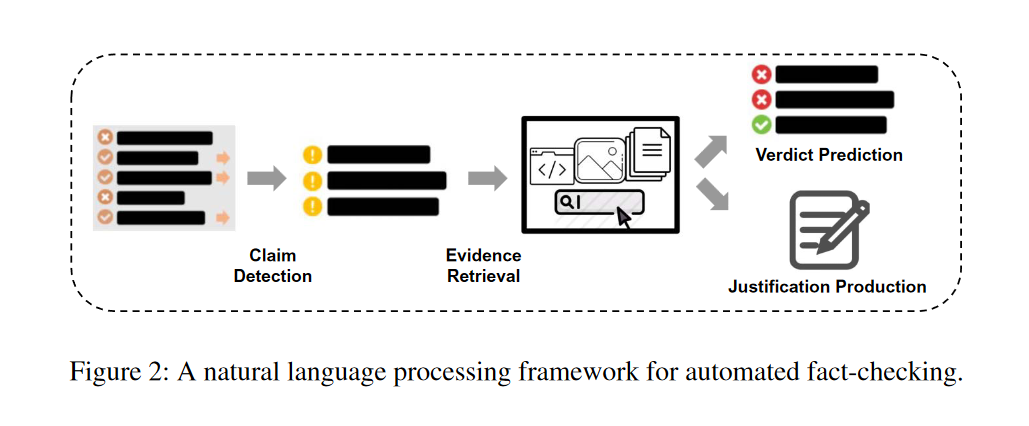
自动证据核查分为三个部分:声明检测,证据取回和声明验证。其中后两个部分一般合称为事实验证。
声明检测
声明检测是挑选句子进行后续验证。检测依赖于可检查性的概念,如挑出的句子应该是公众有兴趣了解真相的声明,或者挑出的句子可能是谣言。这种检查可能是主观的。比如,对于新冠的虚假信息,不同群体的重视程度不同。此外,声明检测的价值随时间的推移而变化。例如,关于 2021 年新冠病毒(COVID-19)的错误信息对社会的影响,要大于关于西班牙流感(Spanish flu)的错误信息。再如,边缘化群体的主张可能受到比来自多数群体的主张更多的审查。声明检测也可以被定义为声明是否对世界做出了可检查的断言。例如,句子“我今天早上 7 点醒来”无法核实,因为无法收集到适当的证据;句子“立体主义艺术很美”也无法核实,因为它是一个主观的陈述。
证据取回
证据取回的目的是找到超出声明范围的信息以表明声明的真实性。证据除了能进行核查外,也能作为判决理由来说服用户。在证据取回中,一个根本问题是不是所有可用的信息都是可信的,所以大多数事实核查方法都隐含的假定可以访问受信的信息源,如百科全书或者由搜索引擎提供并核查的结果。
判决预测
通过给定的声明和检索回来的证据,判决预测试图确定声明的正确性。最简单的是进行二分类(支持/不支持)。有些数据集会采用更细粒度的划分。
辩护生产
事实核查人员需要说服读者相信他们对证据的解释。辩护生产通常依赖以下几种策略:注意力权重可以用来突出证据中的显著部分;也可以将决策过程设计成人类专家可以理解的方式,比如一些基于逻辑的系统;或者将辩护生产建模成一种摘要形式,其中系统为决策生成文本解释。
一种简单的辩护形式是展示证据中的哪些部分被用来做出判决。此外,辩护中应该包含证据是如何被使用的,解释所采用的任何假设或者常识事实,并说明为得到裁决而采取的推理过程。
数据集
输入
典型输入是带有文本内容的社交媒体帖子。第二种类型是由多个Claim组成的文档。
接下来,我们讨论事实验证的输入。最流行的输入类型是文本声明,因为它们通常是声明检测的输出。一般是句子级的陈述,以便只包含与声明相关的上下文。许多现有工作通过从专有辟谣网站爬取真实世界的声明来构建数据集,其他人则主张从特定领域提取声明。
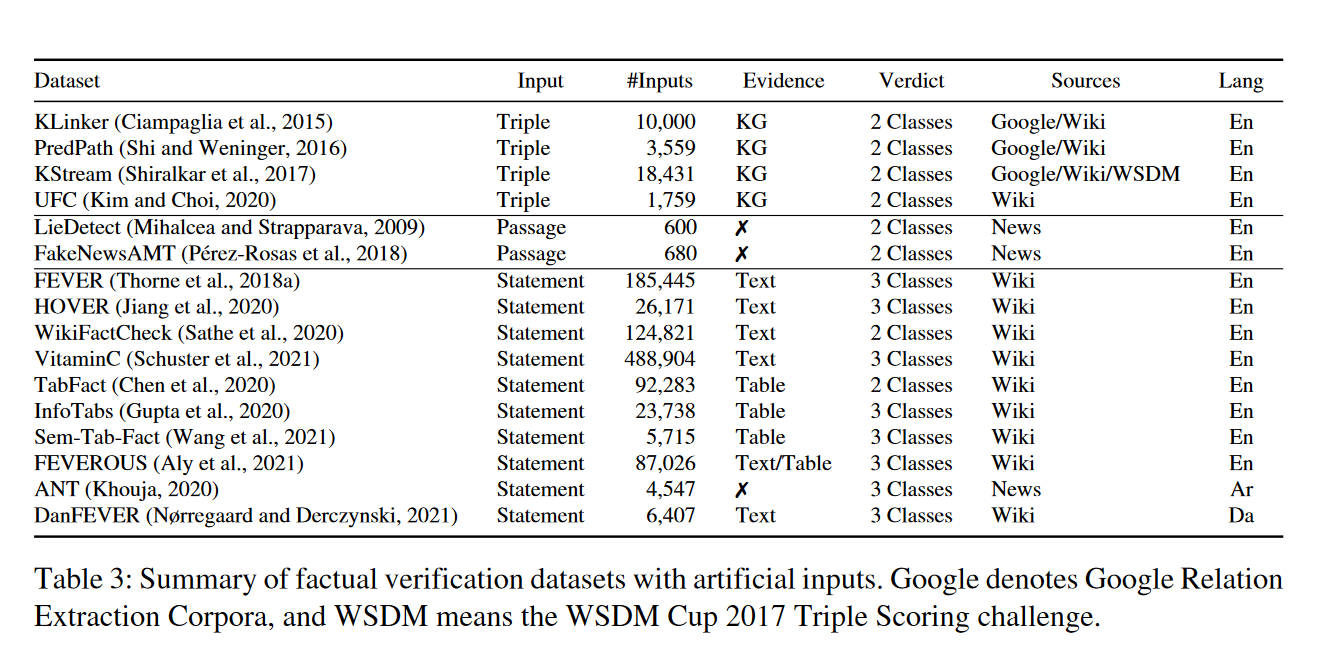
证据
通常考虑的一种证据形式是元数据,例如发布日期,来源,用户配置文件等。虽然它提供了文本来源或结构知识,但是它并没有提供支持这一声明的证据。
文本来源,如新闻文章,学术论文和维基百科文档,是事实核查最常用的证据类型之一。
除了非结构化知识,结构化知识也可以被使用。然而,尽管图的拓扑结构可以作为可能性的一种指标,但它并不能提供决定性的证据。因为不是由图中路径表示的声明,或者由不太可能的路径表示的声明,不一定是错的。知识库的方法假设与声明相关的事实都被呈现在图中,但是即使是最大的知识库中,事实也是不完整的。因此这件事不现实。
另一种类型的结构化知识是半结构化的数据(例如表)。
判决和辩护
不同数据集中的声明的标签数量差距很大,从2个到27个不等。
与只要输出判决的先前数据集不同,FEVER预计输出将包含构成证据的句子和标签,后面的自然和人工数据集也多采用这种形式。
大多数现有数据集不包含有关判决的文字解释。最近,Kotonya 和 Toni (2020b) 构建了第一个明确包含金标准解释的数据集。这些包括事实核查文章和其他新闻项目,可以用于训练自然语言生成模型,为裁决提供事后解释。然而,使用事实核查文章并不现实,因为它们在推理过程中不可用,这使得训练后的系统无法根据检索到的证据提供解释。
模型策略
声明检测
声明检测通常被视作一个分类任务。模型预测声明是否值得检查。
早期的系统使用了带有特征工程的有监督分类器,依赖于如 Reddit 点赞和投票等表面特征(Aker 等人,2017),Twitter 特定的类型(Enayet 和 El-Beltagy,2017),政治讲话中的命名实体和动词形式(Zuo 等人,2018),或者词汇和句法特征(Zhou 等人,2020)。
基于序列或图模型的神经网络方法最近变得流行,因为它们允许模型利用周围社交媒体活动的上下文来指导决策。
证据取回和声明判决
声明判决可以被视为一种文本蕴含识别的形式,预测证据是支持还是驳斥声明。
辩护生成
证明生成方法可以分为三个类别,我们将沿着三个维度——可读性、合理性和忠诚性来检查这些类别。
一些模型包括可以被人类专家分析为理由的组件,主要是注意力模块。选取关注度较高的证据模块作为解释。最近的研究表明,将注意力作为解释是存在问题的。一些具有高注意力得分的标记可以在不影响预测的情况下被移除,而一些具有低(非零)得分的标记实际上却至关重要。因此,注意力提供的解释可能并不足够忠诚。此外,由于这些解释对于非专家和/或没有深入了解模型架构的人来说难以理解,因此它们缺乏可读性。
另一种方法是基于规则使用如知识库之类的工具来构建人类专家可以完全掌握的决策过程。
最后,可以建立像人类专家一样可以为他们决定生成文本解释的模型。但是模型幻觉可能会导致非常误导的理由。
个人感悟
如看。