
embedding 实现
import torch
import torch.nn as nn
import torch.nn.functional as F
# import numpy as np
batch_shape = 10
max_len = 50
dic_len = 300
embedding_dim = 20
# 随机生成batch_shape 大小,最大长度为 max_len 的句子(如果是正常的句子需要自己创建词表并索引化)
src_sen_len = torch.randint(1, max_len, (batch_shape, ))
tgt_sen_len = torch.randint(1, max_len, (batch_shape, ))
src_sen = [F.pad(torch.randint(1, dic_len, (L, )), (0, max_len-L)) for L in src_sen_len]
tgt_sen = [F.pad(torch.randint(1, dic_len, (L, )), (0, max_len-L)) for L in tgt_sen_len]
src_sen = torch.stack(src_sen)
tgt_sen = torch.stack(tgt_sen)
# word_embedding
embedding_layer = nn.Embedding(dic_len+1, embedding_dim)
ebd_src_sen = embedding_layer(src_sen)
ebd_tgt_sen = embedding_layer(tgt_sen)
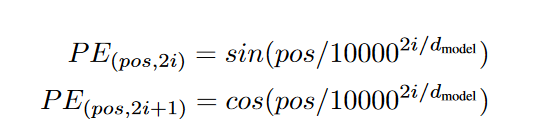
# pos_embedding
pos_mat = torch.arange(0, max_len).reshape(-1, 1)
i_mat = torch.arange(0, embedding_dim).reshape(1, -1)
i_mat = torch.pow(10000, 2 * i_mat / embedding_dim)
pe_mat = pos_mat / i_mat
pe_ebd_table = torch.zeros_like(pe_mat)
pe_ebd_table[:, 0::2] = torch.sin(pe_mat[:, 0::2])
pe_ebd_table[:, 1::2] = torch.cos(pe_mat[:, 1::2])
print(pe_ebd_table.shape)
pos_embedding = nn.Embedding(max_len, embedding_dim)
pos_embedding.weight = nn.Parameter(pe_ebd_table, False)
src_pos = pos_embedding(torch.stack([torch.arange(max(src_sen_len)) for _ in src_sen_len], dim=0))
tgt_pos = pos_embedding(torch.stack([torch.arange(max(tgt_sen_len)) for _ in src_sen_len], dim=0))
print(src_sen_len)
print(src_pos.shape)